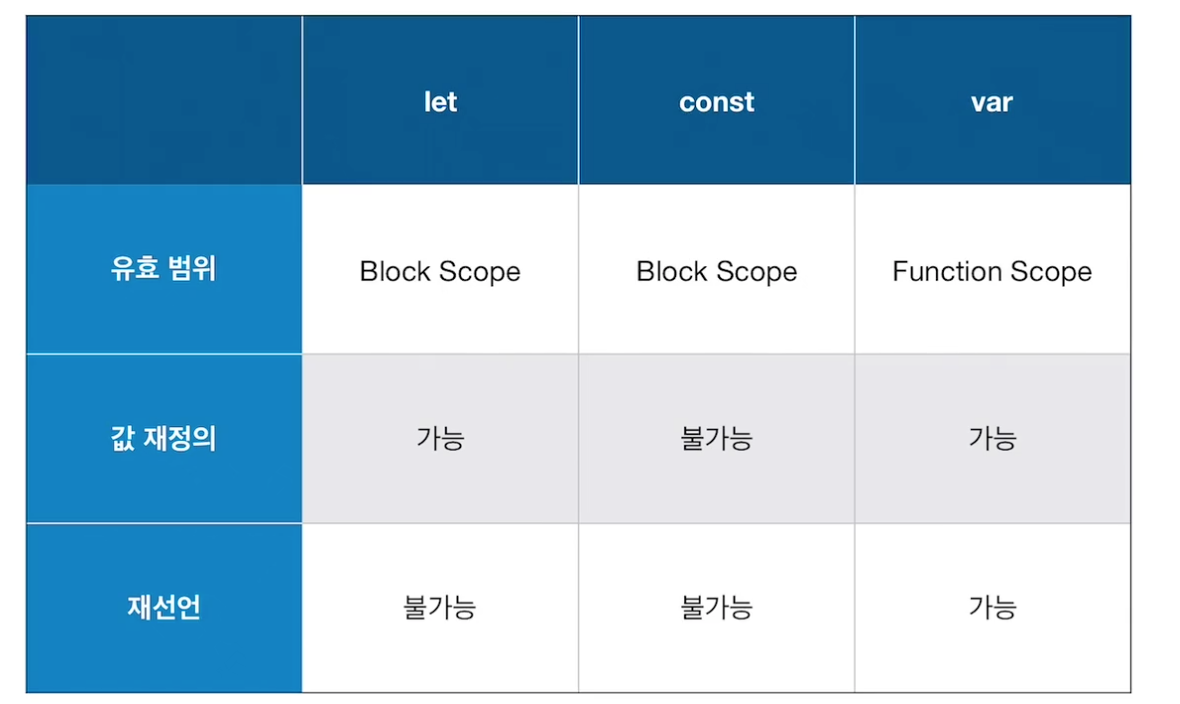
1. 자바스크립트와 타입스크립트의 차이점을 설명해주세요. 자바스크립트는 동적타입의 인터프리터 언어로 런타임에서 오류를 발견할 수 있습니다. 반면 타입스크립트는 정적타입의 컴파일언어로 컴파일타임에 오류를 발견할 수 있습니다. 주요 차이점은 타입시스템의 유무입니다. 자바스크립트는 빠른 코드 작성과 작고 간단한 프로젝트에는 적합하지만, 타입스크립트는 대규모 프로젝트와 유지보수가 필요한 프로젝트에는 더욱 적합합니다. 동적타입은 변수의 타입이 실행 시간에 결정되는 것을 의미합니다. 즉, 변수를 선언할 때 타입을 지정하지 않습니다. 반면 정적타입은 변수의 타입을 컴파일 시간에 결정하는 것을 의미합니다. 즉 변수를 선언할 때 반드시 타입을 지정해야 합니다. 인터프리터 언어는 컴파일 과정 없이 코드를 한 줄씩 읽어가며..